Open-Source Sprogmodeller vs. ChatGPT
Open-Source LLM’er, med deres tilgængelighed og fællesskabsdrevne udvikling, tilbyder en unik blanding af alsidighed og innovation, som muliggør vidtstrakt eksperimentering og tilpasning. ChatGPT, derimod, står som et testamente til målrettet udvikling og forfining, og tilbyder en brugeroplevelse skærpet af omfattende træning og specifikke designmål. Denne artikel fordyber sig i de nuancerede forskelle mellem disse to tilgange, udforsker hvordan hver især opfylder distinkte roller i kunstig intelligens’ verden, og hvordan de former fremtiden for menneske-computer interaktion.
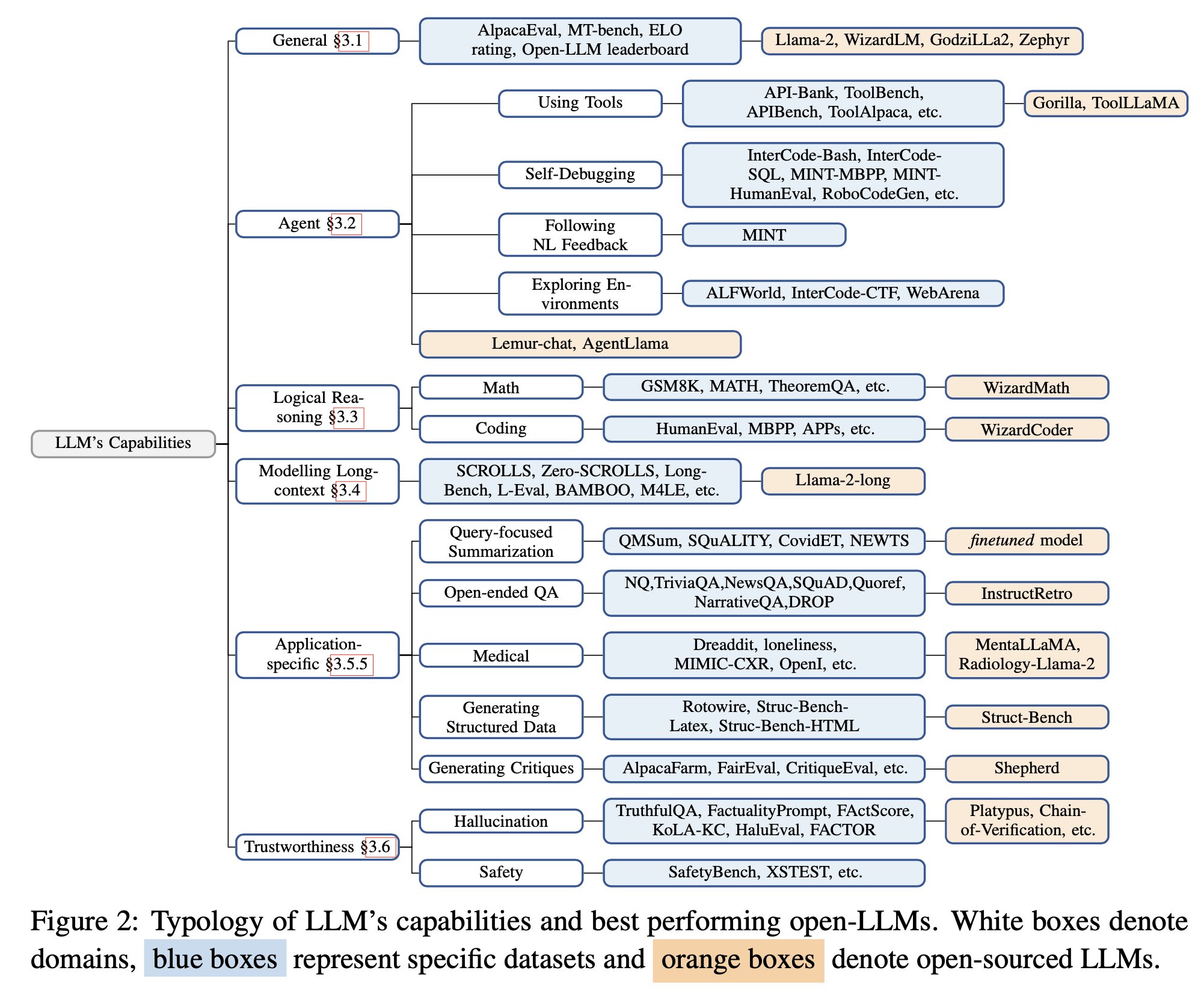
Generelle Evner
Llama-2-chat-70B varianten udviser forbedrede evner i generelle samtaleopgaver, og overgår præstationen af GPT-3.5-turbo; UltraLlama matcher GPT-3.5-turbos præstation i dens foreslåede benchmark.
Agent Evner (brug af værktøjer, selv-debugging, følge naturligt sprog feedback, udforske miljø): Lemur-70B-chat overgår præstationen af GPT-3.5-turbo når det gælder om at udforske miljøet eller følge feedback på kodningsopgaver i naturligt sprog. AgentLlama-70B opnår sammenlignelig præstation til GPT-3.5-turbo på usete agentopgaver. Gorilla overgår GPT-4 i at skrive API kald.
Logiske Ræsonneringsevner
Finjusterede modeller (f.eks., WizardCoder, WizardMath) og fortræning på data af højere kvalitet modeller (f.eks., Lemur-70B-chat, Phi-1, Phi-1.5) viser stærkere performance end GPT-3.5-turbo.
Modellering af Lang-Kontekst Evner: Llama-2-long-chat-70B overgår GPT-3.5-turbo-16k på ZeroSCROLLS.
Applikationsspecifikke Evner
- forespørgsels-fokuseret opsummering (finjustering på træningsdata er bedre)
- åben-ende QA (InstructRetro viser forbedring over GPT3)
- medicinsk (MentalLlama-chat-13 og Radiology-Llama-2 overgår ChatGPT)
- generer strukturerede responser (Struc-Bench overgår ChatGPT)
- generer kritikker (Shepherd er næsten på niveau med ChatGPT)
Tro-værdig AI
Hallucination: under fintuning – forbedring af datakvalitet under finjustering; under inferens – specifikke dekodningsstrategier, ekstern videnforøgelse (Chain-of-Knowledge, LLM-AUGMENTER, Knowledge Solver, CRITIC, Parametric Knowledge Guiding), og multi-agent dialog.
Sikkerhed: GPT-3.5-turbo og GPT-4 modellerne forbliver i toppen for sikkerhedsevalueringer. Dette tilskrives i stor grad Reinforcement Learning med Menneskelig Feedback (RLHF). RL fra AI Feedback (RLAIF) kunne hjælpe med at reducere omkostninger for RLHF.
Læs relaterede artikler:
OptiPrime – Global førende total-performance marketing “mate” for at drive virksomheders vækst effektivt. Løft din virksomhed med vores skræddersyede digitale marketingtjenester. Vi blander innovative strategier og banebrydende teknologi for at målrette din målgruppe effektivt og skabe effektfulde resultater. Vores datadrevne tilgang optimerer kampagner for maksimalt ROI.
OptiPrime strækker sig på tværs af kontinenter og strækker sig fra de historiske gader i Quebec, Canada til det dynamiske hjerteslag i Melbourne, Australien; fra den innovative ånd i Aarhus, Danmark til den pulserende energi i Ho Chi Minh City, Vietnam. Uanset om vi øger brandbevidstheden eller øger salget, er vi her for at guide din digitale succes. Begynd din rejse til nye højder med os!